With the ubiquitous use of online meeting platforms and robust automatic speech recognition systems, meeting transcripts have emerged as a new and interesting domain for natural language tasks. Most recent works on meeting transcripts are restricted to summarization and extraction of action items. However, meeting discussions also have a useful question-answering (QA) component, crucial to understanding the discourse or meeting content, and can be used to build interactive interfaces on top of long transcripts. Hence, in this work, we leverage this inherent QA component of meeting discussions and introduce MeetingQA, an extractive QA dataset comprising questions asked by meeting participants and corresponding responses. As a result, questions can be open-ended and seek active discussions, while the answers can be multi-span and spread across multiple speakers. Our comprehensive empirical study of several robust baselines including long-context language models and recent instruction-tuned models reveals that models perform poorly on this task (F1 = 57.3) and severely lag behind human performance (F1 = 84.6), thus presenting a useful, challenging new task for the community to improve upon.
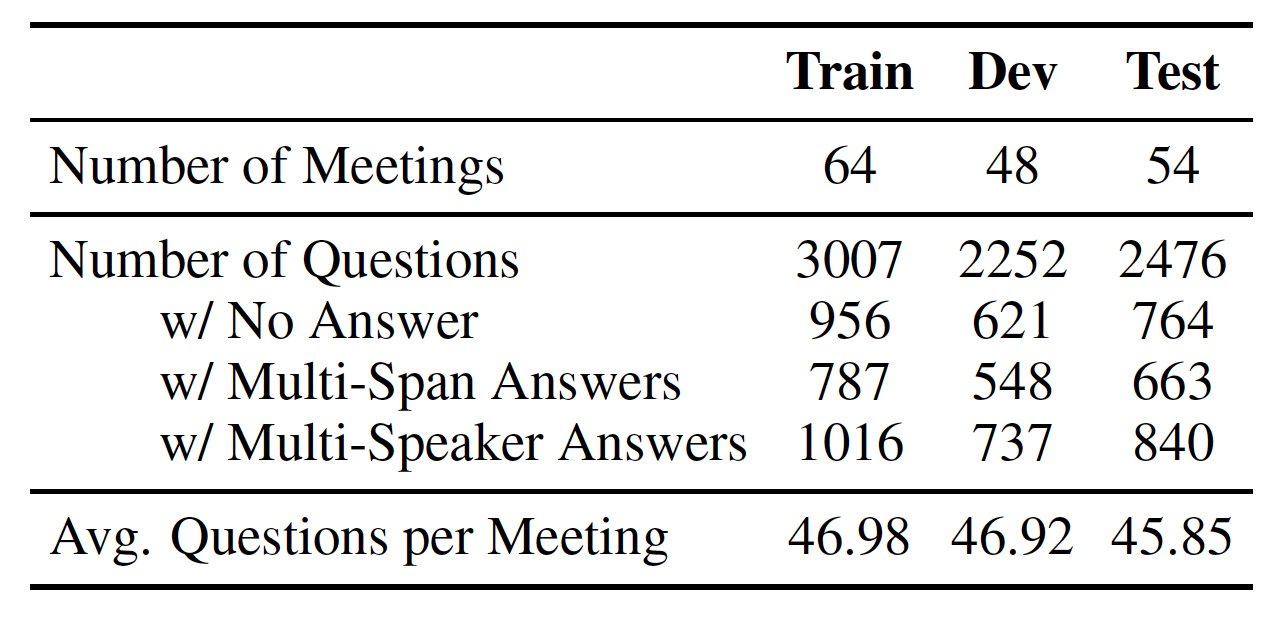

We annotated public meetings from AMI (Augmented Multi-party Interaction) corpus with ~100 hours manually transcribed meetings. To this end, we recruited annotators to label which sentences from the transcript answer each question along with meta-data. We found high inter-annotator agreement with Krippendorff’s α of 0.73, obtaining annotations for 166 meetings at $61 per meeting.
Question Types: Even questions framed in ‘yes/no’ manner are information-seeking and elicit detailed responses, ~50% of questions are opinion-seeking and ~20% are framed rhetorically.
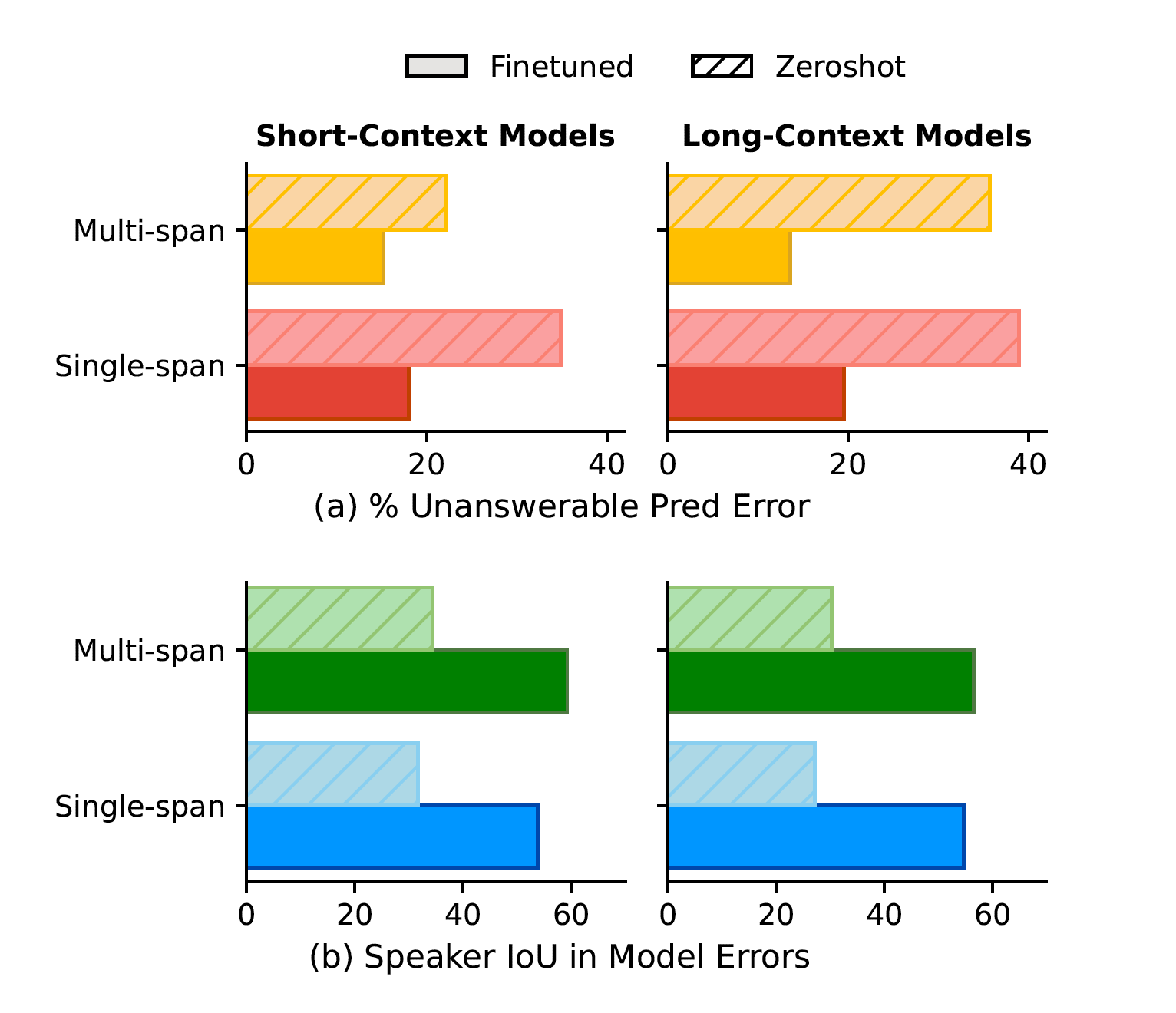
Answer Types: 30% of questions are unanswerable, 40% of answers are multi-span (non-consecutive sentences) and 48% involve multiple speakers. Nearly 70% of multi-speaker answers contain some level of disagreement among participants.
Length Distribution: Average length of a transcript, question, and corresponding answer is 5.9K, 12, and 35 words, respectively.
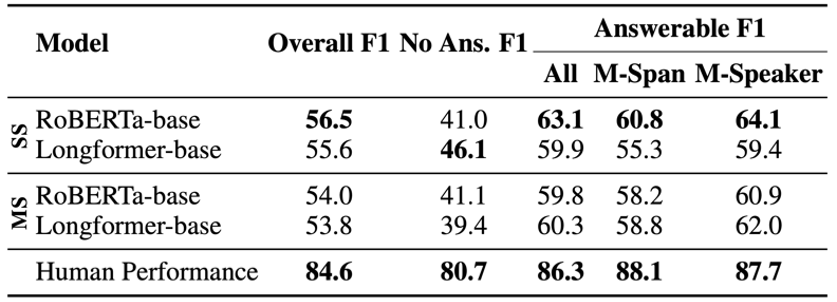
Human Performance: F1=84.6 on 250 questions from the test set.
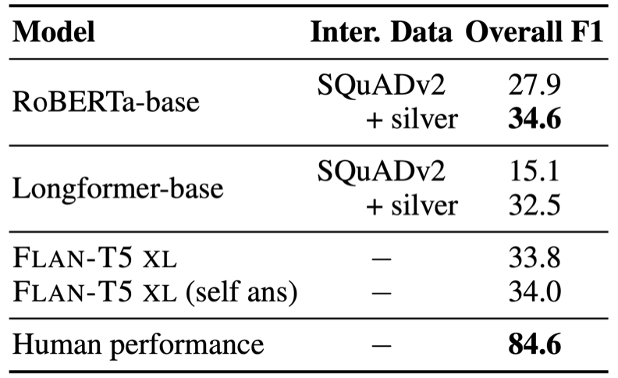
For short-context models, we find that the entire meeting transcripts do not fit in the input context. Thus, we retrieve a segment from transcript based on location of the question. Long-context models on the other hand have longer input context budgets, so for these we fit as much of the transcript as possible (around the question). We explore both single-span models that predict a single-span answer from first to last relevant sentence and multi-span models that treat QA as token-classification task. Additionally, we augment training data with automatically annotated answer spans for interviews from MediaSum dataset.
@article{prasad2023meeting,
author = {Archiki Prasad, Trung Bui, Seunghyun Yoon, Hanieh Deilamsalehy, Franck Dernoncourt, and Mohit Bansal},
title = {MeetingQA: Extractive Question-Answering on Meeting Transcripts},
journal = {ACL},
year = {2023},
}